29/01/2020
15 januari was het weer zover: tijd voor dé jaarlijkse conferentie ‘Operations Research’, met in deze editie het onderwerp ‘Optimization for and with Machine Learning’. Erg interessant voor ons CQM’ers! De toekomst van Machine Learning (ML) biedt geweldige mogelijkheden voor optimalisatieprocessen en omgekeerd. In deze blog delen we de belangrijkste 6 trends die je niet mag missen! Gewoon kort en krachtig en een beetje wiskundig. Neem gerust contact op als je meer wilt weten of benieuwd bent wat dit voor jouw bedrijf kan betekenen in niet-wiskundigentaal…
1. Training versnellen
In de kern van bijna alle Machine Learning technieken zit een gradient descent methode (een klassieke continuous optimization methode). Het is echter vaak duur – in termen van rekentijd – om een optimale oplossing te vinden omdat er een gigantische hoeveelheid knopen in je netwerk zitten en er heel veel trainingsdata is. De optimalisatievraag is namelijk: minimaliseer de loss functie door de gewichten van het neurale netwerk of de coëfficiënten van de voorspellende functie zo goed mogelijk te zetten.
We zagen generieke manieren om snelle benaderingen te geven van deze gewichten/coëfficiënten, waarbij onder bepaalde condities de error ten opzichte van het optimum naar 0 gaat. Kortom: een verbetering van de trainingstijd!
2. Deep neural networks
Wat een goede introductie hoorden we deze dag op het gebied van deep neural networks en welke optimalisatieproblemen er in de kern zitten! We zagen niet alleen wat er opgelost is, maar ook wat er nog op te lossen valt. Om een voorbeeld uit te lichten: vaak leggen data scientists bij slechte resultaten de schuld bij zogenaamde lokale minima, omdat ze vermoeden dat tijdens het trainen van de modellen de optimalisatie in een slecht lokaal minimum vast komt te zitten. Waardoor in de praktijk het model slecht presteert. Er zijn echter sterke vermoedens dat alle lokale minima behoorlijk goed zijn en dus de slechte resultaten aan iets ander toe te wijzen zijn.
Dus, data scientists, geef niet te snel op en denk nog eens goed na over je model, data en methode voor je de schuld geeft aan slechte optimalisatie!
3. Machine Learning en branch & bound trees
Bij het bepalen van de branching strategie moet je algoritme op elke knoop in de branch & bound tree beslissen naar welke knoop gebrancht moet worden. Er is een nieuwe aanpak op dit gebied: leer een machine welke keuze gemaakt moet worden. Klinkt abstract? Valt reuze mee, we hoorden namelijk dat deze aanpak al is geïmplementeerd in de laatste versie van CPLEX.
Met deze aanpak krijg je nog steeds een optimale oplossing en doordat het algoritme in kan schatten welke zoekstrategieën wel en niet zullen werken kom je sneller tot de optimale oplossing.
4. Auto Machine Learning: voorspellingen doen
Voor sommige problemen zijn veel verschillende algoritmes beschikbaar. Soms is de ene beter, soms de andere. Door een algoritme selector (een met Machine Learning getrainde beslisser) en vervolgens het geselecteerde algoritme toe te passen gaat de gemiddelde performance enorm omhoog. Het is dus mogelijk om te voorspellen welk algoritme op welke instantie het beste zal presteren!
Dit betekent dat we niet 1 algoritme hoeven te ontwikkelen die gemiddeld goed werkt, maar dat het een betere optie kan zijn om een aantal (eenvoudigere) algoritmes te maken die soms heel goed presteren, en dan in combinatie met een algoritme selector als geheel beter presteren.
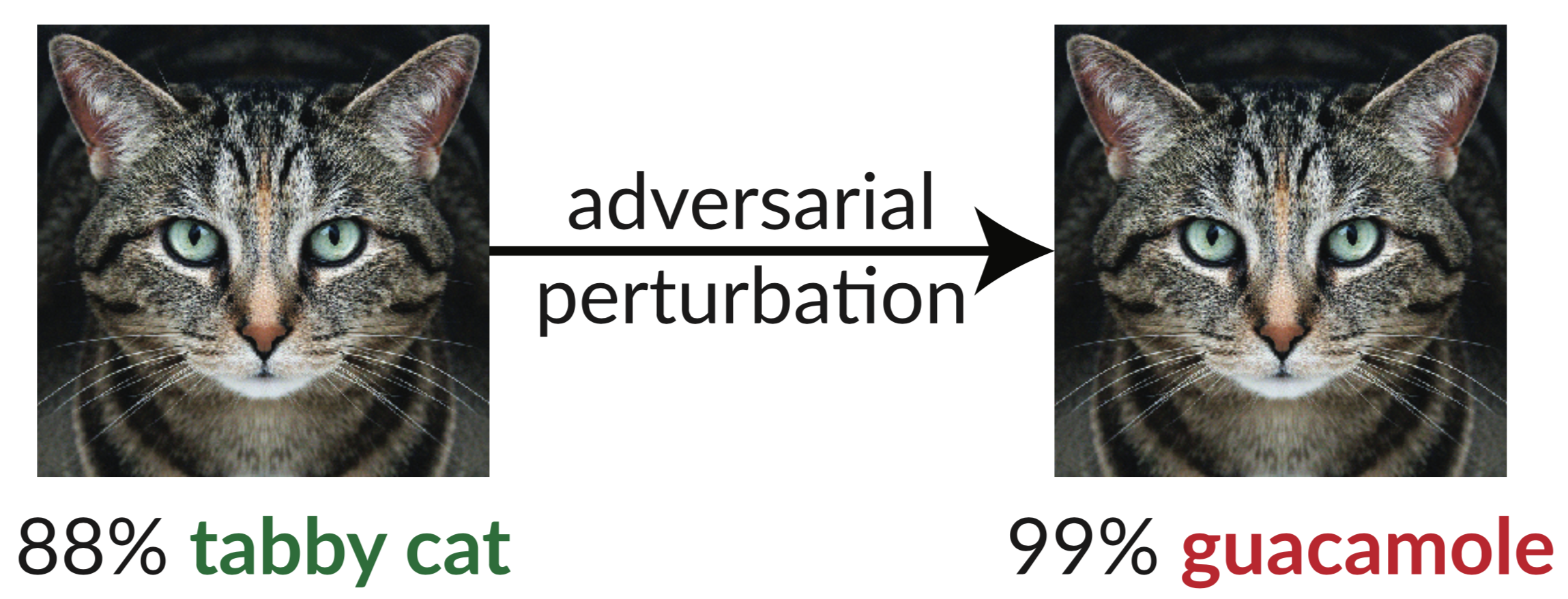
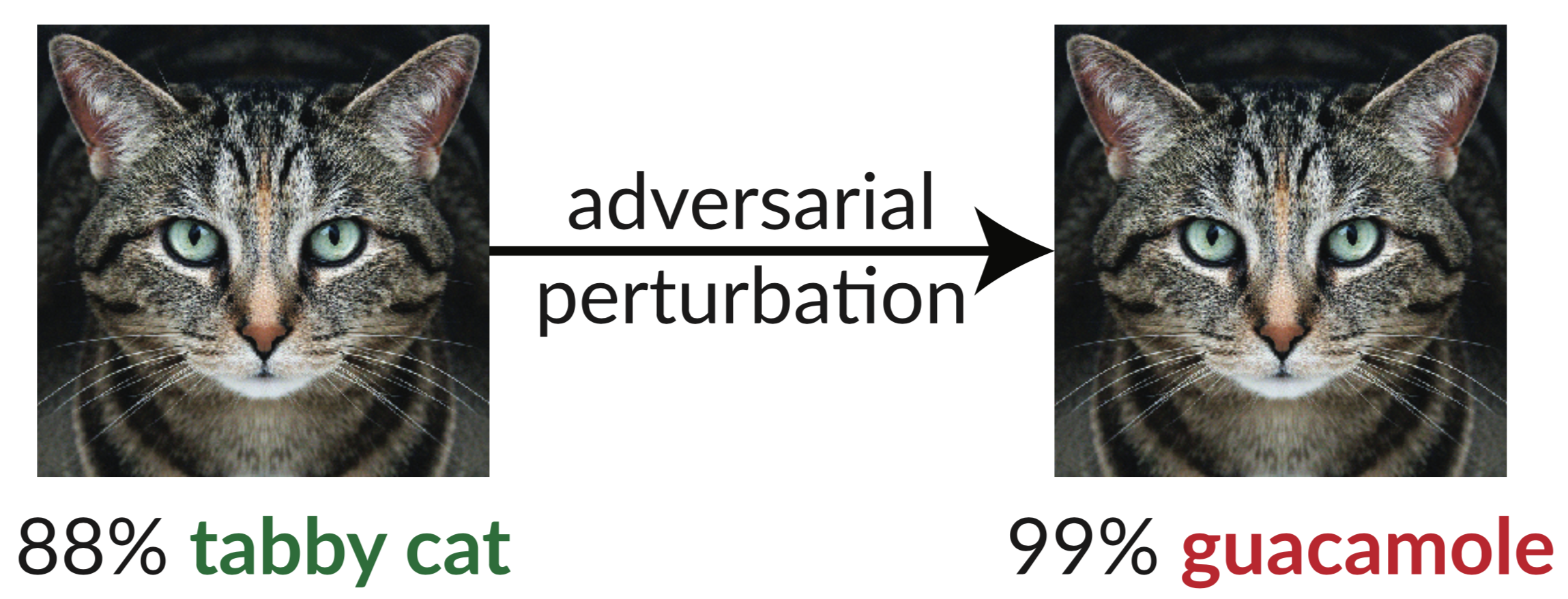
5. De robuustheid in Machine Learning
Een prachtig verhaal hoorden we over de robuustheid in ML, met name in beeldherkenning. Een klassiek voorbeeld is een plaatje van een kat + een beetje ruis, dat wordt geclassificeerd als een guacamole, terwijl je als mens het verschil niet ziet. Een machine wel. Een hilarisch maar eigenlijk belachelijke uitkomst. We zagen hoe je de training aan kan passen zodat het bestand is tegen dit soort ruis. Hierdoor ben je robuuster, wat betekent dat je algoritme in de praktijk beter presteert. Benieuwd hoe je de training robuuster maakt? Laat het me weten J
6. Machine Learning trainen om optimale oplossingen te schatten
Op dit moment wordt er door de Nederlandse overheid een gebied op de Noordzee aangewezen voor windmolenparken. Dan is het aan de bouwer van het park hoe ze dat gebied het best kunnen benutten. Maar wat als dit een vrij te kiezen gebied wordt? De vraag gaat dan van “Hoe bouw je hier zo efficiënt mogelijk een windmolenpark?” naar “Waar en hoe bouw je zo efficiënt mogelijk een windmolenpark?”.
De gekozen aanpak is om met behulp van ML van een gegeven gebied te voorspellen wat de waarde van een optimale oplossing zal zijn (dus niet waar de molens precies moeten komen). Dan is van elk gebied heel snel te bepalen of het interessant is of niet, zonder daar een kostbare optimalisatie op te doen. De trainingsdata wordt in dit geval gemaakt door een groot aantal gesamplede gebieden te optimaliseren om zo de features naar de waarde van de optimale oplossing te mappen.
Meestal zien we dat Machine Learning modellen data voorspellen wat daarna input is voor een optimalisatie probleem. Hier zien we optimalisatie de data voor Machine Learning genereren. Een verrassende en waardevolle aanpak!
Kortom: een wederom inspirerende conferentie zoals we al zeiden. Benieuwd naar de mogelijkheden van Machine Learning binnen jouw organisatie? De koffie staat klaar, we sparren er graag een keer over!
Wil je op de hoogte blijven van het laatste nieuws van CQM, volg ons op LinkedIn of meld je aan voor onze digitale nieuwsbrief.
Meer achtergrond en presentaties van deze conferentie zijn terug te vinden op: https://www.lnmb.nl/conferences/2020/announcementngblnmbseminar/
Fotocredit: Pixabay

