
Lees verder
Datum: 28 nov 2018
Diepe neurale netwerken zijn tegenwoordig opmerkelijk goed in het maken van voorspellingen. De automatische beeldherkenning van CQM en Inspectation is daar een voorbeeld van. Maar hoe kunnen we erop vertrouwen dat zo’n systeem goed zal werken in de praktijk? De complexe algoritmes van netwerken zijn vaak lastig te doorgronden (black box) en daardoor moeilijk te controleren of beoordelen op betrouwbaarheid. Ook de methodes om de prestatie van een neuraal netwerk te bepalen, zoals een F1-score, bevatten ingewikkelde algoritmiek. Dit zorgt voor onzekerheid die bijvoorbeeld in kritieke gebieden (waar de gevolgen groot kunnen zijn) als geneeskunde, de financiële sector of het strafrechtelijk systeem, niet acceptabel is en leidt tot een afwachtende houding. En dat is jammer. Want Deep Learning (processen automatiseren en optimaliseren die tot voor kort enkel door mensen konden worden uitgevoerd) biedt zo veel kansen! Daarom maken we bij CQM gebruik van een intuïtieve beoordelingsmethode: we visualiseren waar een neuraal netwerk op let wanneer het een voorspelling maakt.
Wanneer is een (diep) neuraal netwerk goed genoeg? Om te bepalen hoe goed een neuraal netwerk presteert gebruiken we statistieken, zoals precisie, een Kappa-score of een F1-score. Daarmee meten we hoeveel voorspellingen er goed of fout worden gemaakt tijdens de ontwikkeling (training) van een neuraal netwerk, zodat we kunnen bepalen of het netwerk van zijn fouten leert. In een grafiek, zoals een ROC-curve, is dan af te lezen hoe goed het netwerk presteert na een training.
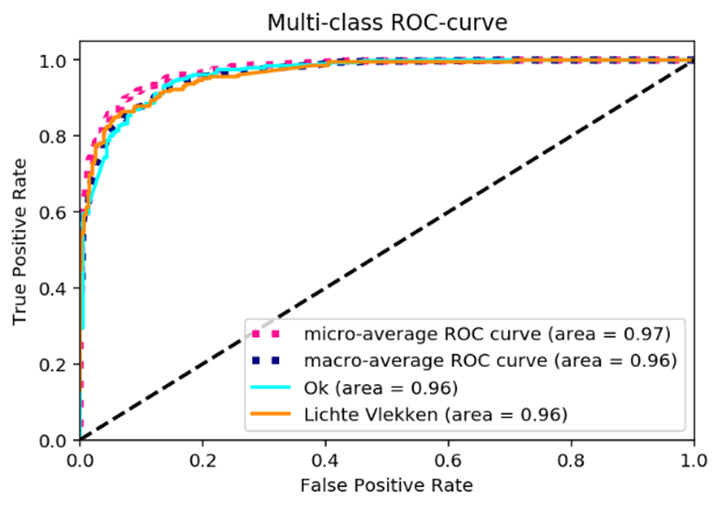
Voorbeeld van typische grafiek voor neurale netwerken: Deze ROC-curve geeft aan hoe goed plaatjes gedetecteerd worden die behoren tot één van twee verschillende categoriëen: “Ok” of “Lichte Vlekken”, in contrast tot willekeurige gokken (de diagonale zwarte lijn).
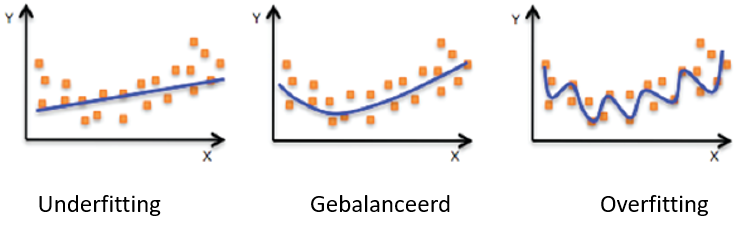
Toch kan het voorkomen dat sommige statistieken positief uitslaan terwijl het neurale netwerk slecht zou presteren in de praktijk. Dat kan worden veroorzaakt door problemen zoals het zogenoemde overfitting of underfitting, wat meestal een gevolg is van het gebruik van een ontoereikende dataset of een netwerkstructuur die niet in staat is genoeg belangrijke kenmerken van de input te leren. De volgende afbeelding geeft een voorbeeld van een functie die aan deze problemen lijdt:
Om te achterhalen of problemen als overfitting voorkomen en waar dat precies aan ligt, is inzicht in de beredenering van het netwerk nodig. Ook hiervoor bestuderen we statistieken, zoals de omvang van de inschattingsfout die een neuraal netwerk maakt tijdens de training. Hoe meer dat afwijkt, hoe sterker de variabelen van het netwerk moeten worden aangepast. Dat gebeurt met optimalisatie. De waarde van de afwijking van een neuraal netwerk wordt berekend met backpropagation. Maar om te begrijpen waar de fout ligt en hoe groot deze is, moet een gebruiker dus wel goed begrijpen hoe backpropagation werkt.
Of… we maken het visueel! Om de kwaliteitscontrole goed te begrijpen is CQM op zoek gegaan naar een aanvullende beoordelingsmethode die intuïtief te begrijpen is: feature visualization.
Een feature is een vakterm voor een kenmerk van de input data dat herkend wordt door het neurale netwerk. Dat kan gaan over een bepaald patroon in een afbeelding, maar ook over een woord uit een stuk tekst. Het doel van een neuraal netwerk is om zo goed mogelijk te worden in het herkennen van features van de input. Door tijdens de netwerktraining de gedetecteerde features te bestuderen kunnen we de voortgang van een neuraal netwerk meten. En als we de features visualiseren kunnen we beredeneren waarom een bepaalde uitkomst werd geleverd.
Zo wordt het eenvoudig zichtbaar wanneer gevonden features bijvoorbeeld niet logisch zijn voor de taak die we een neuraal netwerk willen laten uitvoeren en kan het neurale netwerk worden geoptimaliseerd totdat we voldoende verbetering in zien.
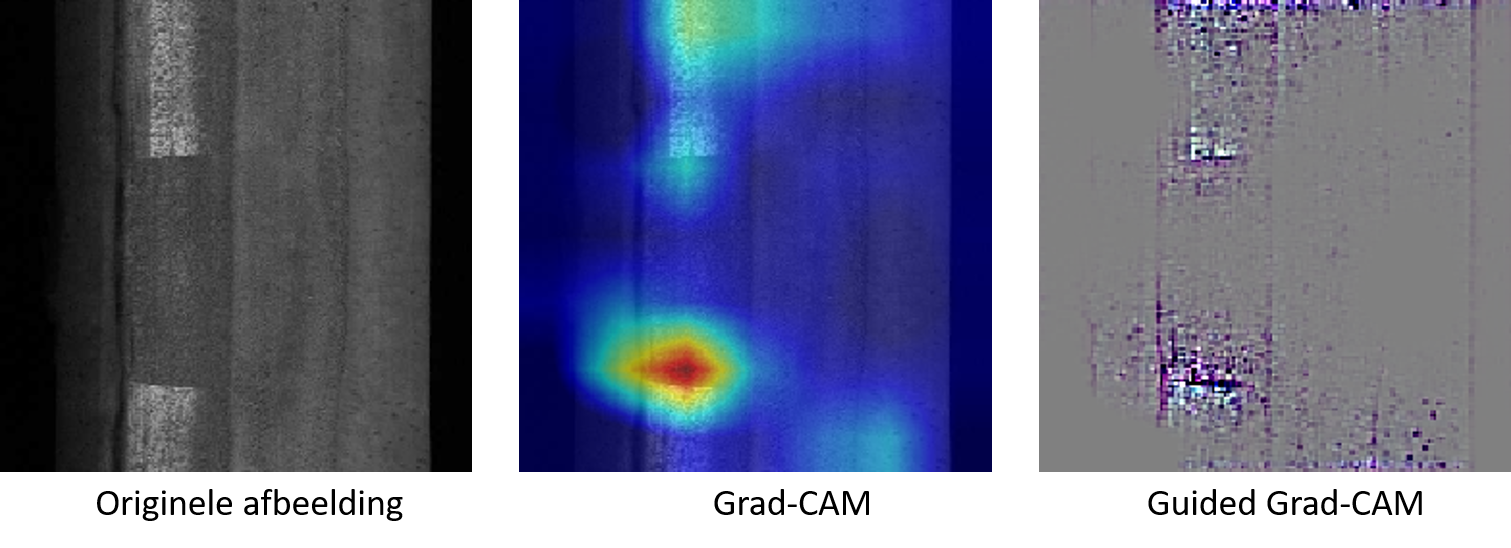
In het onderstaande voorbeeld kreeg een netwerk de taak om thermietlaslijnen van een treinspoor te herkennen. Voor de visualisatie zijn verschillende technieken gebruikt: Grad-CAM en Guided Grad-CAM. De heatmap van Grad-CAM geeft aan in hoeverre het netwerk bepaalde (gebieden van) pixels belangrijk acht voor de geleverde voorspelling. Hoe ‘heter’ de pixels, hoe belangrijker de pixels waren om tot de gegeven conclusie te komen. Guided Grad-CAM geeft binnen de gebieden van Grad-CAM een nauwkeurigere indicatie van belangrijke pixels aan. Hierdoor was te zien dat de thermietlaslijnen door het netwerk juist werden gevonden.
In de afbeeldingen hieronder is te zien dat een ander netwerk de thermietlaslijnen uit hetzelfde plaatje niet goed herkent. Toch gaf het netwerk aan dat dit plaatje thermietlaslijnen bevat:
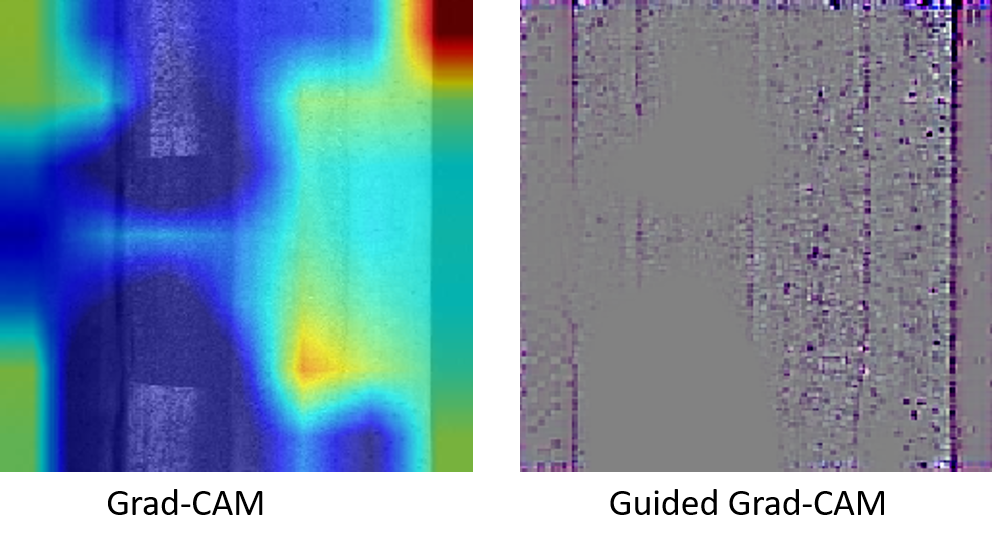
Door deze visualisatie is het in één oogopslag duidelijk of een neuraal netwerk beter getraind moet worden. Daarnaast geeft het aan of een bepaald neuraal netwerk beter is dan een ander, terwijl ze beide exact dezelfde voorspelling leveren.
CQM gebruikt dit soort visualisatietechnieken om samen met de gebruikers te bepalen of een neuraal netwerk naar wens presteert, zonder dat hier diepgaande statistische kennis van de gebruikers voor nodig is. Op deze manier kunnen we onzekerheid over de betrouwbaarheid van diepe neurale netwerken wegnemen en wordt de toepassing ervan een stukje toegankelijker.
CQM heeft de juiste hardware, software, kennis en enthousiasme in huis om samen met uw organisatie het gebruik van Deep Learning tot een zakelijk succes te maken!
Op de hoogte blijven van het laatste nieuws? Volg ons op LinkedIn of meld u aan en beheer hier de mailing die u van CQM wilt ontvangen.
Lees verder

Lees verder

Lees verder