
Lees verder
Datum: 15 jul 2020
Eerst een kleine introductie van de annotatietool en het doel waarvoor deze is ontwikkeld. In de scriptie is gewerkt met geannoteerde reviews van elektronische apparaten. Hieronder een voorbeeld van een review van een navigatiesysteem:
“When fully charged the battery only lasts 2 days. The navigation is useless when you’re driving a long time. Have bought a new charger. Will keep this as a spare.”
Deze review is eerder gelezen door iemand en ‘geannoteerd’ op de verschillende drivers. In deze review worden twee van deze drivers behandeld, namelijk ‘Batterijduur’ en ‘Accessoires’. Over beide onderwerpen is de review negatief, maar over ‘Batterijduur’ iets minder dan over ‘Accessoires’. Daarom heeft het ene onderwerp -1 (negatief) en het andere -2 (zeer negatief) als score gekregen. De andere drivers worden niet besproken en daarom wordt geen score toegekend. Wanneer dit proces voor meerdere reviews gedaan wordt, leidt dit tot een tabel met de volgende vorm, waarbij NA staat voor ‘geen score toegekend’. Je ziet dus dat de driver ‘Design’ een NA krijgt bij onze voorbeeld review:
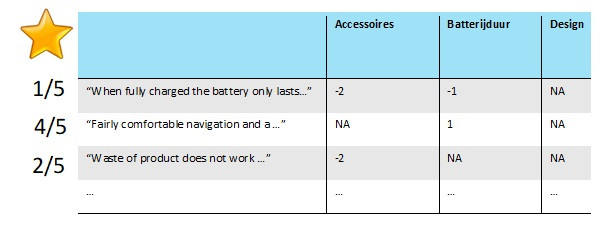
Stel dat de 1e en 3e review uit het bovenstaande tabelletje bijvoorbeeld slechts 1/5 en 2/5 scoren, dan zou je gebaseerd op dit voorbeeld kunnen stellen dat een negatieve driver score voor ‘Accessoires’ vaak gepaard gaat met een negatieve star rating.
Deze conclusie is echter wat voorbarig, want hij is op slechts 3 reviews gebaseerd. Als we dit voor honderden of duizenden reviews doen kunnen we conclusies trekken die wél geloofwaardig zijn en kan daarmee bepaald worden aan welke drivers nog gewerkt moet worden om de star rating omhoog te krijgen. CQM heeft hiervoor speciale statistische modellen ontwikkeld die op basis van dit soort geannoteerde data identificeren welke drivers sterk van invloed zijn op de overall star rating.
Zoveel reviews handmatig lezen en annoteren kost echter heel erg veel tijd. En zo komen we bij het onderwerp van de scriptie: gegeven de geannoteerde reviews, kunnen we het annoteren van nieuwe reviews automatiseren? Kunnen de driver scores voor nieuwe reviews automatisch worden bepaald, zonder dat iemand ze moet lezen?
Als eerste stap richting het voorspellen van de driver scores proberen we simpelweg te voorspellen of een review over een gegeven driver gaat of niet. We kijken bijvoorbeeld naar de driver ‘Accessoires’ en zetten dan een 1 neer voor de 1e review uit het voorbeeld, die over deze driver gaat, en een 0 voor de 2e review, die niet over deze driver gaat. Zo krijgen we voor elke driver een rijtje van 0-en en 1-en en we willen in staat zijn om deze te voorspellen. Dit noemen we een binair classificatieprobleem. Dit binaire probleem is niet direct de eerder geformuleerde doelstelling, maar het kan ook al nuttig zijn als het systeem deels geautomatiseerd is, en een voorstel geeft over welke onderwerpen al dan niet worden besproken.
Om te kunnen voorspellen moeten we de vrije tekst in de reviews omschrijven naar nuttige data. We verwachten dat bepaalde woorden in de review inzicht bieden in of een review over een zekere driver gaat of niet. Gebruik van het woord ‘battery’ duidt er bijvoorbeeld op dat de review over ‘Batterijduur’ gaat. Dus, we tellen simpelweg het aantal keer dat elke woord wordt gebruikt. Dit combineren met het rijtje 1-en en 0-en geeft de volgende tabel:
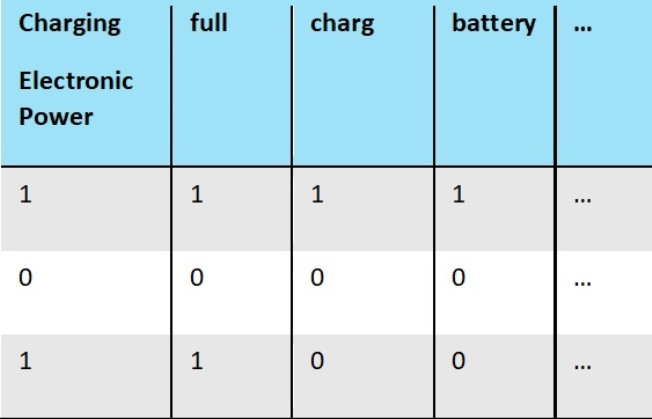
Hier zijn twee dingen gebeurd:
Wat hebben we nu? Een rijtje met 1-en en 0-en en heel veel waardes voor de woorden. Nu moet nog de stap naar het voorspellen van de 1-en en 0-en worden gemaakt, gebruikmakend van de woorden. Hiervoor moet een model gekozen worden.
Er is met twee typen modellen gewerkt uit de Machine Learning: Elastic nets en Random forests. We ‘trainen’ deze modellen op de reviews die al geannoteerd zijn. Dit betekent dat ze, elk op hun eigen manier, het verband tussen de woorden en de te voorspellen 0-en en 1-en beschrijven en dit kunnen gebruiken om, gegeven de woorden in een nieuwe review, een nieuwe 0 of 1 kunnen voorspellen.
Deze modellen zijn gekozen omdat ze relatief goed met het hoog aantal variabelen (=woorden) in dit probleem om kunnen gaan. Daarnaast bieden beiden ook nog inzicht in welke woorden belangrijk zijn voor het voorspellen van de 1-en en 0-en.
Met bovenstaande methode waren we in staat om te voorspellen of een review over een driver gaat (voorspel een 1) of niet (voorspel een 0). Het uiteindelijke doel gaat verder: het voorspellen van de driver scores: -2, -1, 1, 2 of NA. Het verschil tussen -1 en -2 en tussen 1 en 2 is erg lastig te zien, zowel voor mens als voor computer.
We kunnen wel proberen te voorspellen of de driver score positief of negatief is of een NA. Omdat we dan dus niet 1-en en 0-en, maar P (positief), N (negatief) en NA proberen te onderscheiden hebben we niet meer een binair classificatieprobleem maar een multinomiaal classificatieprobleem. Dit multinomiale probleem komt wel met de nodige haken en ogen. Zo moeten de modellen worden aangepast en andere evaluatie methodes zijn nodig. Na dit gedaan te hebben is het ons uiteindelijk ook gelukt om P, N en NA te onderscheiden.
We kunnen terugkijken op een geslaagd resultaat. Niet alleen is het gelukt om driver presence te detecteren, maar ook het bijbehorend sentiment kan voorspeld worden. Voor een daadwerkelijke implementatie van het automatiseren zal nog het een ander moeten gebeuren, maar de basis is zeker gelegd.
Het verschil tussen -1 en -2 laten detecteren zal altijd lastig blijven, maar het kunnen onderscheiden van 0 en 1 of P, N en NA kan het proces al deels automatiseren, wat ook al erg veel tijd bespaart. Wanneer de techniek uit dit project hiervoor wordt gebruikt moeten er nog wel enkele ‘parameters’ worden afgesteld. Wil je, als annoteerder, bijvoorbeeld liever dat het systeem wat meer 1-en voorspelt, en dat er af en toe eentje fout is, of andersom en meer 0en?
Daarnaast is het soms lastig te onderscheiden of een review over de ene of de andere driver gaat, zowel voor mens als computer. Omdat eerder beschreven modellen altijd ‘getraind’ worden op de door mensen geannoteerde reviews, en deze niet altijd consistent geannoteerd zijn, is het lastig om voor een computer dan ‘correct’ te voorspellen of een review over een driver gaat of niet. Mensen oordelen soms verschillend over welke driver een review gaat. Als het gaat over de instructies van een navigatiesysteem, gaat het dan om gebruiksgemak of duidelijkheid? Bijvoorbeeld of de spraak helder is, het scherm goed af te lezen is of over hoe de instructie geschreven is? Hier is onder mensen discussie over, dus het is ook niet vreemd dat een algoritme hier dan moeite mee heeft. Kortom: meer consistentie in de data helpt, maar dit aanbrengen is niet altijd eenvoudig.
Desondanks presteren de modellen behoorlijk en kunnen we, zoals eerder gezegd, terugkijken op een geslaagd resultaat waarin de basis is gelegd. Persoonlijk kan ik ook terugkijken op een erg mooie stageperiode bij CQM. Ik heb aan erg interessant project mogen werken waarin ik veel van mijn studie kon toepassen en heb daarnaast veel fijne en gedreven collega’s leren kennen en met hen samen mogen werken.
- Jos -
Wil je op de hoogte blijven van het laatste nieuws van CQM, volg ons op LinkedIn of meld je aan voor onze digitale nieuwsbrief.
Ben je student en wil je stagelopen bij CQM? Stuur dan je motivatiebrief, CV en cijferlijst(en) naar info@cqm.nl of vul hier het formulier in (bij open sollicitatie).
Lees verder

Lees verder

Lees verder