
Lees verder
Datum: 22 feb 2024
Amazon koos ervoor om een algoritme te ontwikkelen dat geen gebruik maakt van iemands geslacht. Klinkt goed, maar het probleem bestond al in de dataset die hiervoor gebruikt werd: een dataset aan keuzes tot wel of niet aannemen van potentiële werknemers bij eerdere Amazon-sollicitaties. Deze keuzes waren namelijk niet eerlijk, mannen werden vaker aangenomen dan vrouwen met dezelfde capaciteiten. Het resulterende algoritme nam deze tendens over, door typisch vrouwelijke en mannelijke eigenschappen te gebruiken. Zo werden bijvoorbeeld kandidaten van uitsluitend-vrouwen-universiteiten afgewezen, dat werkt immers goed op de gebruikte dataset!
Eerlijk gezegd vinden wij, vanuit een moreel en ethisch perspectief, het gebruik van zo’n algoritme een slecht idee. Maar stel dat we dit specifieke probleem zouden willen oplossen, is dat mogelijk? Het antwoord is ja: met de causaliteit theorie van Judea Pearl kunnen we het algoritme zo aanpassen dat het gegarandeerd niet beïnvloed wordt door iemands geslacht.
De eerste stap is om een oorzaak-gevolg diagram op te stellen die overeenkomt met het ontstaan van de data. Het diagram hieronder vangt de essentie van het probleem. Het geslacht van een kandidaat had invloed op de beslissing tot aannemen, maar bijvoorbeeld ook op school- en studiekeuze en hobby’s, die op hun beurt weer invloed hadden op deze beslissing. De aanpak van Amazon, het geslacht negeren, komt dus niet overeen met de data. De invloed van geslacht kan in die aanpak niet meer langs de rode lijn stromen, maar zal desondanks via de paarse lijn naar de andere kandidaatseigenschappen stromen en zo toch invloed uitoefenen op de beslissing. Dit fenomeen wordt door statistici een confounder genoemd, en komt in veel vraagstukken voor.
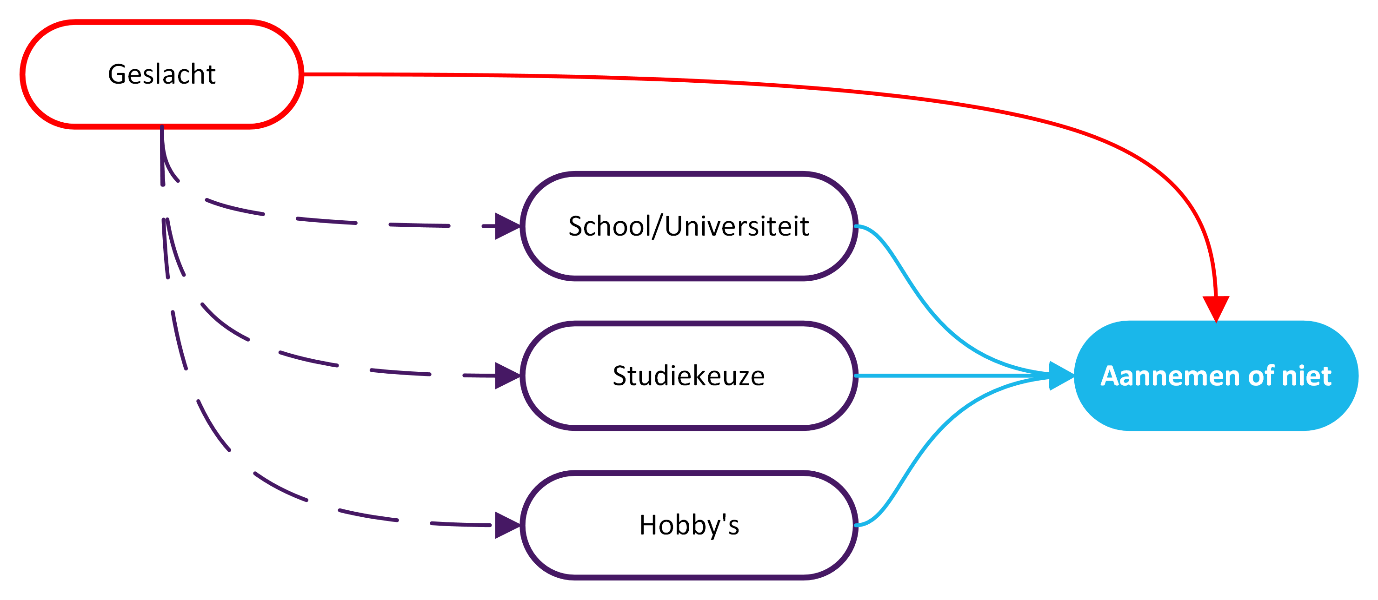
De volgende stap is om een algoritme te ontwikkelen, waarbij zowel het geslacht als andere eigenschappen meegenomen worden. Dit algoritme is dus niet eerlijk: het geslacht beïnvloed de keuzes van het algoritme. Echter kan hiermee wel de échte invloed van de andere kandidaatseigenschappen als school, studiekeuze en hobby’s bepaald worden.
Nu willen we de situatie bekijken waarin toekomstige kandidaten niet beoordeeld worden op hun geslacht. In het diagram zijn de rode pijlen dus ongewenst, alleen de blauwe pijlen zijn relevant. De causaliteit theorie van Judea Pearl vertelt ons hoe we dit moeten bewerkstelligen. Hier is het eenvoudig: we liegen tegen het algoritme en zeggen altijd dat een kandidaat een man is (of vrouw, of nemen het gemiddelde van de keuzes). Het lijkt een trucje, maar hiermee is er gegarandeerd geen invloed van iemands geslacht op de uitkomst van het algoritme. Ook niet indirect, zoals plaatsvond bij Amazon. Klinkt simpel? Ja, maar de machine learning experts bij Amazon hadden hier niet aan gedacht.
Nou zijn veel meer problemen met het gebruik van een algoritme om te bepalen of je iemand wel of niet wil aannemen, dus willen we het gebruik hiervan sterk afraden. Maar dit voorbeeld laat wel zien hoe begrip en gebruik van causaliteit ons helpt in het uitsluiten van ongewenste invloed in onze analyses en voorspellingen. Daarom zit de causaliteit van een vraagstuk altijd in ons achterhoofd als we aan het werk zijn bij CQM!
CQM organiseert donderdagmiddag 21 maart 2024 een symposium over causaliteit: “Beyond coincidence: understanding causality”. Voor iedereen die data verzamelt, analyseert en/of visualiseert... Heb je interesse om het symposium bij te wonen (let op: we lopen tegen de maximum capaciteit aan), neem dan contact op met: Martijn Gijsbers.
Wil je op de hoogte blijven van het laatste nieuws van CQM, volg ons op LinkedIn of meld je aan voor onze digitale nieuwsbrief.
Lees verder

Lees verder

Lees verder