
Lees verder
Datum: 28 jan 2019
At CQM we are passionate about working out complex problems for our customers. Usually the problems have something to do with data science. Well underway in our projects, we usually get to the technical bit. Personally, I like a technical challenge, but let me emphasize that sometimes we can give some profound insights using only simple tables or plots after having asked the right questions to the right people. For this blog however, I focus on a challenging situation: somewhere along the way, we study the relation between some consequence and many candidate predictors, but, at the same time, have relatively few observations.
Over the past years, we have come across a wide variety of examples with few observations compared to the number of predictors.
If you have many observations (n), say n > p2, where p denotes the number of inputs, then good old linear regression might work. With much fewer observations, you run the risk of overfitting the model. For a simple example, 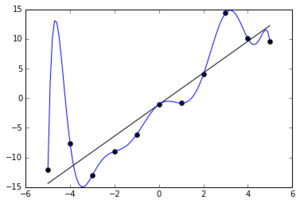 consider just one (i.e., p = 1). Suppose you fit a complex model, the blue line. This model would be way too complex. It fits the data perfectly, but you would expect that the next 1000 points lie scattered around the straight line rather than the blue line. With only one predictor, the solution is easy: only use simple shapes. However, with many predictors, we will suffer from the curse of dimensionality, and even simple linear models are likely to generalize poorly to future observations. In the classical statistical setting, generalization to future predictors is less of a concern. However, in our context where we would like to understand the relation between y and many predictors, having only few observations, we should stay on the safe side and only consider models that are future-proof.
consider just one (i.e., p = 1). Suppose you fit a complex model, the blue line. This model would be way too complex. It fits the data perfectly, but you would expect that the next 1000 points lie scattered around the straight line rather than the blue line. With only one predictor, the solution is easy: only use simple shapes. However, with many predictors, we will suffer from the curse of dimensionality, and even simple linear models are likely to generalize poorly to future observations. In the classical statistical setting, generalization to future predictors is less of a concern. However, in our context where we would like to understand the relation between y and many predictors, having only few observations, we should stay on the safe side and only consider models that are future-proof.
Data science, machine learning, and statistics give a wide variety of techniques for building a model linking an output y to inputs xi, say y = f(x1, ..., xp). No matter how advanced the technique, in practice you usually need domain knowledge (substantive knowledge, expert knowledge) to get to a successful model. In the situation where you have few observations compared to the number of candidate predictors, this is even more important.
In the upcoming two blogs, we will publish possible approaches to deal with the challenging situation of many predictors and few observations, with their pitfalls and things to consider, as well as some typical tools used in such situation.
Blog 2 - Many predictors, few observations – Dimension reduction and regularization.
Ook interessant:
Op de hoogte blijven van het laatste nieuws? Volg ons op LinkedIn of meld u aan en beheer hier de mailing die u van CQM wilt ontvangen.
Lees verder

Lees verder

Lees verder